Quang-Tien Dam
Finetuning Gr00t-N1.5 on Libero Synthesis Dataset
TL;DR:
- Don’t finetune for too long
- Bigger batch size is better
- Should use 4 denoise steps
- Did not outperform Pi-zero
- Need to tune midway planning for better performance
Recently, I became excited about a generalist vision-language-action model called Gr00t-N1 by Nvidia. They introduced me to the idea of VLA models, which provide intuition of language and vision from a VLM model to an action generation model. However, I learned that Gr00t is not the first of its kind—I found this very helpful blog that explains the development of VLA research thoroughly.
In this post, I will report my experience trying to finetune Gr00t-N1.5 on the Libero Synthesis Dataset.
Short introduction
-
Gr00t is a generalist robot action generation model, which has a VLM and a diffusion generation head. The VLM was trained on an internet-scale dataset and can understand the relationship between visual information and language instructions. In inference, the VLM produces meaningful embeddings that contain context information, then the diffusion head takes those embeddings and previous observations of its state to generate the next chunk of actions.
-
Libero is a synthesis dataset built to tackle the problem of lifelong learning in robotics with the idea of learning a generalist agent that learns and adapts over time. It contains different task sets to test policies in terms of spatial, object, goal understanding and long-horizon tasks. Libero provides an easy-to-run environment and model evaluation.
Before training
The OpenVLA paper includes clear guidance and process to use Libero to test the model. It also released the test results for 3 models: Diffusion Policy, Octo, OpenVLA. So for a fair comparison and effort saving, I will use the same dataset as in OpenVLA to finetune Gr00t.
Initially, I found a very helpful script from the repository of OpenPI to process the original dataset into the state of OpenVLA. Then, I cloned the original dataset and let it process. However, it said that it would take me the whole day to just change the format of the dataset. Apart from this, I also collected the results of Pi-0 and Pi-fast from here as baselines.
Fortunately, I found another preprocessed dataset on HuggingFace that is ready to use. More conveniently, it is already in the format of LeRobot dataset, which is the format Gr00t requires. So I decided to solely use this dataset to train Gr00t.
Gr00t requires a definition of the new dataset to be defined in a file called modality.json in the meta folder of the dataset. I found a helpful issue where people share their config file and experience in training Gr00t on Libero, so I just reused them.
Let’s train
I use a 3080 that has 10 GB of VRAM and it could only fit to train with LoRA 32 and batch size 1. Originally, I had a pair of them, but the second one got so hot that it killed the whole training process.
From the original readme of Gr00t, they stated to “boost the batch size to the max, and train for 20k steps.” To resemble the effect of big batch size, I can use multiple devices, using grad accumulation. I ran a few training jobs just to realize it would take the whole day for a single run.
However, I still wanted to test the model capabilities when finetuned with the least hardware that I have. So I set LoRA 32 and batch size 1 and let it run for 30k steps. To my surprise, the finetuning process ran very fast, it only took roughly 1 hour to finetune on each subset of Libero on my machine. But there is no low hanging fruit here, the evaluation result for this run was disappointing.
Therefore, I run more with longer training for 50k steps, and try to boost the batch size and lora rank. The final results are reported in the following table.
| LIBERO-Spatial | LIBERO-Object | LIBERO-Goal | LIBERO-Long (10) | |
|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 |
| Octo finetuned | 78.9 | 85.7 | 84.6 | 51.1 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 |
| π0-FAST @ 30k (finetuned) | 96.4 | 96.8 | 88.6 | 60.2 |
| π0 @ 30k (finetuned) | 96.8 | 98.8 | 95.8 | 85.2 |
| Groot N1.5 @ 30k, lora 32, b1 (finetuned), 3080 | 89.0/68.2 | 83.8/86.0 | 87.8/78.2 | 46.2/31.6 |
| Groot N1.5 @ 50k, lora 32, b1 (finetuned), 3080 | 69.8/40.0 | 62.2/55.6 | 64.0/59.4 | 25.9/17.6 |
| Groot N1.5 @ 30k, lora 64, b16 (finetuned), 4060ti, 3090 | - | 96.4/96.0 | - | 67.4/64.0 |
| Groot N1.5 @ 30k, full, b32 (finetuned), A6000 | - | - | - | 53.0/77.0 |
*Results show two separate training runs with the first value being replanning of 5 and the latter value being no replanning. Color coding: Red = 1st place, Yellow = 2nd place, Blue = 3rd place (ranked by column).
Gr00t-N1 does not outperform the baseline of π0 in any metrics. I thought it was due to the replanning configuration, so I also tried with no replanning, however changing replanning seems to have unclear effects on the final performance.
Longer training with 50k steps may hurt the performance, this is also reported by someone on the huggingface. It seems that training too long will make the model forget what it has learnt and “ignore the text prompt”.
Bigger batchsize is generally better, which is consistent with the author’s advice. However, it comes with the cost of hardware and longer training time. I could only afford to run limited times on those bigger hardware.
Further experiments
In this part, I use the hardest task set in the libero dataset to get a bigger effect in asserting the model performance. And I could only do full rank training once for this task.
Does more denoising steps help with the model performance?
I ran evaluation with denoising step of 4, 8 and 16, and reported results in the following figure.
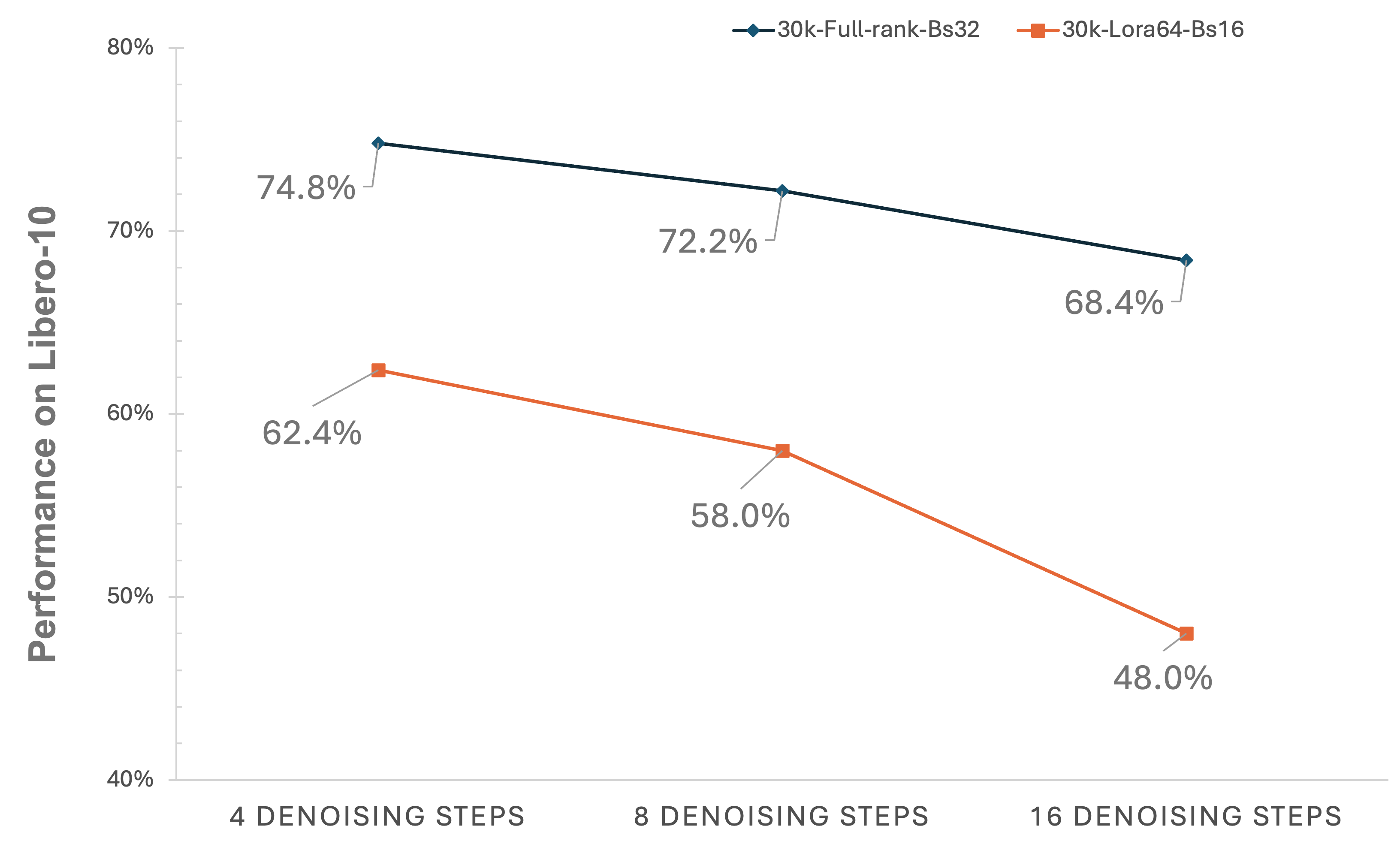
It is quite clear from the results that increase the number of denoising steps hurt the model performance. This is counter intuitive for me that, theoritical speaking, the more steps the better quality the generation should be. However in this task the model seems to fail for longer and better generation.
My current explanation for this is that when it have longer denoise steps it will generate too precise position of the robot and also it may be too overfit into the training dataset. So that it lose the generality and fail the tasks.
Does replan midway affect the model performance?
Replanning midway means that after a number of execution steps the model will see new observation and produce new motion sequence. The smaller replanning steps mean the more frequent the model got to see feedback from the environment and produce more grounded motion. However, it would produce jitteriness and imprecise trajectory when transferring between two windows of sequence.
I tested three different checkpoints (fullrank, lora64 and lora32) on Libero-10. As illustrated in the chart, the lora64 and fullrank model performances are comparable and better than the performance of lora 32 with batch size 1.
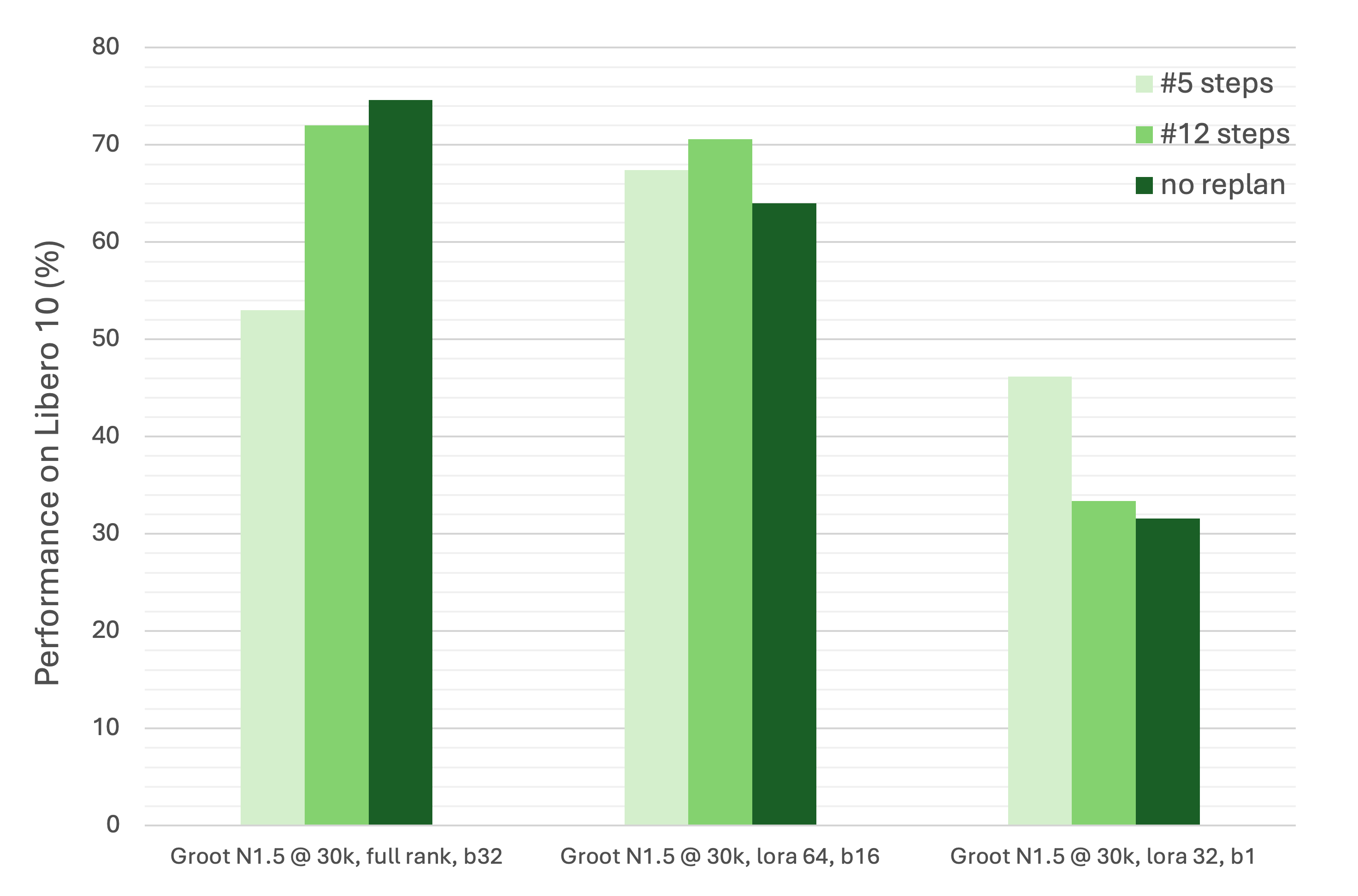
However, the performance of the fullrank checkpoint with 5 replan steps is far too low compared to other checkpoints. And the lora 32 checkpoint with 5 replan steps has a big margin compared to 12 steps and no replanning. While the lora64 checkpoint’s performance for three options are stable.
For the better performance, one should conduct a parameter search to make the best performance out of the model.
Code
I log the necessary code in two repositories:
In the Gr00t repository, I add the data config that to process the Libero dataset. And also store the modality.json for Libero dataset in the root directory of the repo. To finetune, you can just clone this repo, clone the dataset from HuggingFace, and copy the modality.json to the meta folder of the dataset. Then finetuning with the following call:
python scripts/gr00t_finetune.py --dataset_path path/to/community_libero_object --data_config libero
I make use of the libero evaluation code in this repository, and change the policy call to make it compatible with the inference_service.py of Gr00t.
I prepare a batch script to call both the gr00t inference service and evaluation environment.
While I was conducting this experiment, the repository of Gr00t has updated and provided official support to test on Libero synthesis dataset. The results provided there is consistent with what I got from this post, so for an easier path, you can just follow the steps there to reproduce the results here.
Conclusion
Gr00t-N1 is a promising genralists model for cross-embodiment motion generation. The model outperformed many previous methods such as Diffusion Policy, Octo, and OpenVLA while loss to Pi0 and Pi0-fast.
Miss but an hour's fated meeting, and lifetimes pass before next greeting.